7月25日,英特尔发布了新的 APX(高级性能扩展),同时还披露了新的 AVX10,它将首次为 P 核和 E 核提供统一的 AVX-512 功能支持。也标志着被英特尔在12、13代酷睿中枪毙的AVX 指令集运算功能回归。AVX-512为何能卷土重来?

不得不提的ALU
在了解 AVX-512 指令集之前,有必要先了解一下 ALU 的工作原理。
顾名思义,算术处理单元用于执行数学计算任务。这些任务包括加法、乘法和浮点计算等运算。为了完成这些任务,ALU 使用由 CPU 时钟信号驱动的特定应用数字电路。

因此,CPU 的主频就决定了 ALU 处理指令的速度。因此,如果 CPU 的时钟频率为 5GHz,那么 ALU 在一秒钟内可以处理 50 亿条指令。因此,CPU 的性能会随着时钟频率的提高而提高,但CPU 产生的热量也会增加。
那么,新一代处理器如何提供比旧版处理器更好的性能呢?人们开始利用并行概念来提高性能。这种并行性可以通过使用多核架构来实现,即使用多个不同的处理内核来提高 CPU 的计算能力。

另一种提高性能的方法是使用 SIMD 指令集。简单地说,“单指令、多数据”的指令方式,可以让 ALU 在不同的数据点上执行相同的指令。这种并行方式可以提高 CPU 的性能,AVX-512 就是一种 SIMD 指令,用于提高 CPU 在执行特定任务时的性能。

什么是 AVX-512,它如何工作?
AVX 512 指令集是 AVX 的第二次迭代,于 2013 年进入英特尔处理器。作为高级矢量扩展(Advanced Vector Extensions)的缩写,AVX指令集最早出现在英特尔至强Phi(Knights Landing)架构中,后来在英特尔服务器处理器Skylake-X CPU中使用。
此外,AVX-512 指令集通过 Cannon Lake 架构进入基于消费类的CPU,后来又得到 Ice Lake 和 Tiger Lake 架构的支持。
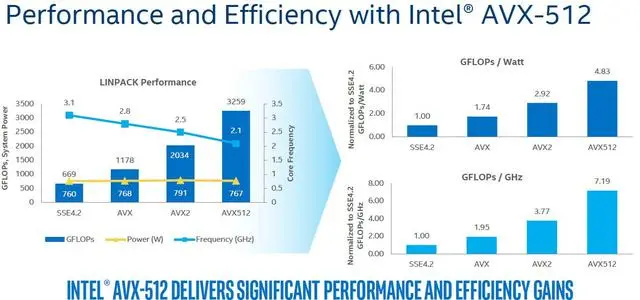
该指令集的主要目标是加速涉及数据压缩、图像处理和加密计算的任务。AVX-512 指令集的计算能力是旧版指令集的两倍,性能大幅提升。
那么,英特尔是如何将使用 AVX-512 架构的 CPU 性能提高一倍的呢?
如前所述,ALU 只能访问 CPU 寄存器中的数据。高级矢量扩展指令集增加了这些寄存器的大小。

由于寄存器容量的增加,ALU 可以在一条指令中处理多个数据点,从而提高了系统性能。
就寄存器大小而言,AVX-512 指令集提供 32 个 512 位寄存器,与旧版 AVX 指令集相比增加了一倍。
因此,只需执行一条指令,就可以同时进行多项操作,而不必以标量方式(即逐个数据)进行操作。例如,可以同时对 8 个 64 位数据或 16 个 32 位数据进行操作,等等。
英特尔为什么要终止 AVX-512?
如前所述,AVX-512 指令集具有多项计算优势。事实上,像 TensorFlow 这样的流行AI开发库都使用了该指令集,以便在支持该指令集的 CPU 上提供更快的计算速度。
而对于浮点运算极度依赖的加密解密计算、文件压缩和解压缩、音频视频编码解码以及复杂的3D渲染来说,AVX-512的性能提升是比较大的。也就是说,对生产力用户来说,只要软件支持,那么AVX-512对性能提升是很明显的。
即使是对于3A大作,由于复杂的3D和AI计算,这种并行指令集对帧率的提升也是有帮助的。而诸如游戏主机模拟器等虚拟化计算场合,其意义也非常大。

那么,英特尔为什么要在最近的12、13代酷睿处理器上禁用 AVX-512呢?
因为这两代处理器与英特尔生产的旧处理器不同。旧系统使用的是运行在同一架构上的内核,而这两代酷睿处理器使用的是两个不同的内核,也就是异构运算技术。Alder Lake 处理器中的这些内核被称为 P 核和 E 核,采用不同的架构。
P 核心使用 Golden Cove 微架构,而 E 核心使用 Gracemont 微架构。当特定指令能在一种架构上运行而不能在另一种架构上运行时,这种架构上的差异就会妨碍调度程序的正常运行。
在 Alder Lake 处理器中,AVX-512 指令集就是这样一个例子,因为 P 核心拥有处理该指令的硬件,而 E 核心却没有。
因此,Alder Lake 处理器不支持 AVX-512 指令集。
尽管如此,AVX-512 指令仍可在某些英特尔未将其物理融合的 Alder Lake CPU 上运行。要做到这一点,用户必须在 BIOS 中禁用 E 核。

相反,由于采用非异构运算结构,AMD在Ryzen7000 CPU上,反而支持起了AVX-512,似乎也是一种小小的讽刺。

AVX10如何恢复AVX-512支持?
新的 AVX10 ISA 并不支持英特尔当前一代的 CPU,但它使英特尔同时拥有 E 核和 P 核的芯片仍然支持 AVX-512,尽管 512 位指令只能在 P 核上运行。同时,融合的 256 位 AVX10 指令可以在 P 核或 E 核上运行,从而使整个芯片仍然支持 AVX-512 功能。
不过,e-cores 将仅限于融合 AVX10 的最大 256 位向量长度,而 P-cores 可以使用 512 位向量。这感觉类似于 Arm 的 SVE 对可变向量宽度的支持。
AVX10 推出后,英特尔将冻结 AVX-512 ISA,今后 AVX-512 指令的所有使用都将通过 AVX10 ISA 进行。
